
Цель состоит в том, чтобы сделать простое, но уже ценное предсказание.
pandas - библиотека для загрузки и манипулирования данными
numpy - библиотека для работы с векторами / матрицами, pandas внутри также использует `numpy`
sklearn - библиотека, которая содержит конкретные реализации алгоритмов машинного обучения (произносится как *[saɪ-kit-lə:n]*, это сокращенная версия от `"science-kit-learn"`)
ПОШАГОВОЕ ВИДЕО ДЛЯ ДАННОГО УРОКА:
pandas - библиотека для загрузки и манипулирования данными
numpy - библиотека для работы с векторами / матрицами, pandas внутри также использует `numpy`
sklearn - библиотека, которая содержит конкретные реализации алгоритмов машинного обучения (произносится как *[saɪ-kit-lə:n]*, это сокращенная версия от `"science-kit-learn"`)
ПОШАГОВОЕ ВИДЕО ДЛЯ ДАННОГО УРОКА:
Определение пола по имени
Код
import pandas as pd
#модели (алгоритмы)
from sklearn.dummy import DummyClassifier # <== Простейшая возможная модель
from sklearn.linear_model import LogisticRegression # <== Логистическая (линейная)регрессия
#метрика успеха
from sklearn.metrics import accuracy_score
Внимание! наименование модели (LogisticRegression) указывает, что это логистическая регрессия, в то время как это подкласс линейной регрессии (то есть это обычная линейная регрессия + дополнительная функция в конце).
Мы загружаем данные
Данные в формате .csv, pandas позволяет загружать данные в формате .csv => .read_csv(). в одну строку. При запуске этой строки df будет содержать данные, загруженные из файла в табличной форме (то есть строки и столбцы).
в конце).
Данные в формате .csv, pandas позволяет загружать данные в формате .csv => .read_csv(). в одну строку. При запуске этой строки df будет содержать данные, загруженные из файла в табличной форме (то есть строки и столбцы).
в конце).
Код
df = pd.read_csv("../input/polish_names.csv")
df.head()
Результат:
Мы проверяем данные
Для начала мы хотим знать очень простые вещи:
Для начала мы хотим знать очень простые вещи:
- Сколько строк (всех объектов)?
- Сколько столбцов (признаков объектов)?
- Какая переменная является целевой переменной?
- Какая проблема должна быть решена (классификация или регрессия)?
- Для классификации, сколько (два или более) и какие уникальные значения имеет целевая переменная?
- Как выглядит распределение уникальных значений целевой переменной (это примерно поровну или всё-таки есть очень популярные/редкие классы)?
- Есть ли недостающие данные?
Код
df.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1705 entries, 0 to 1704
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 name 1705 non-null object
1 gender 1705 non-null object
dtypes: object(2)
memory usage: 26.8+ KB
RangeIndex: 1705 entries, 0 to 1704
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 name 1705 non-null object
1 gender 1705 non-null object
dtypes: object(2)
memory usage: 26.8+ KB
- Вторая строка "показывает": 1705 entries, то есть количество строк (объектов).
- Третья строка "показывает": total 2 columns, что означает, что у нас есть 2 столбца (признаки).
- У нас есть информация о каждом столбце и количество значений ('non-null').
- Если столбец X имеет меньше null строк, чем целое, это означает, что для этой функции у нас есть отсутствующие значения (англ. missing data), с которыми Тебе придется иметь дело.
- В нашем случае (вначале) все очень просто. У нас есть все значения и только один признак - имя. А второй столбец - это целевая переменная (англ. target variable), то есть имя мужское или женское (только два значения, поэтому двоичная классификация).
- Последняя строка по использованию памяти показывает, сколько оперативной памяти используется, в данном случае очень мало (только 26.7 KB).
Как выглядят данные?
Смотрим 10 случайных строк.
Смотрим 10 случайных строк.
Код
df.sample(10)
Результат:
- Столбец name содержит имена, и иногда довольно интересные:).
- Столбец gender содержит пол, где m обозначает мужское имя a f - женское имя
Код
df['gender'].value_counts()
Результат:

- Мужских имен почти в 2 раза больше (1033 vs 672).
- Дальше будет видно, есть ли у нас какие-то проблемы (например, из-за того, что женских имен меньше, качество модели хуже. Если да, то мы потом подумаем, что с этим делать).
Помни, что модель ожидает числового представления, а не строкового? Теперь мы должны преобразовать m => 1, f => 0.
Функция map. Чтобы лучше понять, как работает функция .map(), давай сделаем это в несколько шагов.
Функция transform_string_into_number возвращает то же самое, что она получила, - это так называемая функция функция идентификации. Мы делаем это для того, чтобы узнать синтаксис.
Код
def transform_string_into_number(value):
return value
df['gender'].head().map( transform_string_into_number )
Результат:

Теперь давай добавим логику в функцию transform_string_into_number
Код
def transform_string_into_number(value):
return int(value == 'm')
df['gender'].head().map( transform_string_into_number )
Результат:

Теперь давай использовать анонимную функцию (lambda), чтобы уменьшить количество кода. Результат сопоставления присваивается новому столбцу с именем target.
Обрати внимание, что lambda не имеет ключевого слова return, потому что это по определению должно быть однострочной логикой (результат, который будет возвращен).
Обрати внимание, что lambda не имеет ключевого слова return, потому что это по определению должно быть однострочной логикой (результат, который будет возвращен).
Код
df['target'] = df['gender'].map( lambda x: int(x == 'm') )
df.head(10)
Результат:
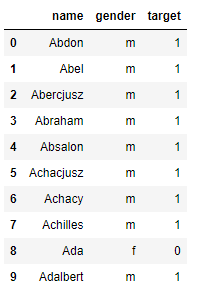
Построение признаков
Добавим первый признак, например, это будет длина имени. Предположим, что количество букв может повлиять на предсказание того, является ли имя мужским или женским.
Почему именно так? С чего - то мы должны начать, и это один из самых простых признаков, который можно сделать для слова. Эффективен ли он? Это то, что мы хотим проверить.
Добавим первый признак, например, это будет длина имени. Предположим, что количество букв может повлиять на предсказание того, является ли имя мужским или женским.
Почему именно так? С чего - то мы должны начать, и это один из самых простых признаков, который можно сделать для слова. Эффективен ли он? Это то, что мы хотим проверить.

Задание 1.3.1
Твоя задача - создать новый признак (столбец), который будет содержать длину имени (можно создать более одного признака, если у Тебя есть идеи для этого).
В уроке курса (на сервере Jupyter) для задания предусмотрена подсказка и ответ - по умолчанию скрыты :))
Твоя задача - создать новый признак (столбец), который будет содержать длину имени (можно создать более одного признака, если у Тебя есть идеи для этого).
В уроке курса (на сервере Jupyter) для задания предусмотрена подсказка и ответ - по умолчанию скрыты :))
Первая модель
Давай подготовим данные
Метод, отвечающий за обучение модели, называется: fit и ожидает 2 аргумента:
Подсказка:
- Давай сделаем нашу первую модель (англ. basic model), которая будет довольно простой, совершенно "глупой", впрочем, она и соответствует своему названию DummyClassifier.
- Очень рекомендую начать с чего-то очень простого, это поможет понять, где Ты сейчас и увидеть первый результат, с которым мы можем сравнивать (например, если позже мы проведем несколько недель, делая что-то более продвинутое, в некоторых случаях может стоило бы применить только самую простую модель?)
- Идея в том, что модель смотрит только на целевую переменную, как часто встречаются те или иные признаки (в нашем случае: мужское или женское имя).
Давай подготовим данные
Метод, отвечающий за обучение модели, называется: fit и ожидает 2 аргумента:
- Первый аргумент это матрица/массив признаков (Примечание: функция может быть одна, но это все еще должен быть массив, а не вектор!)
- Второй аргумент- вектор целевой переменной (англ. target variable)
Подсказка:
- [1, 2, 3, 4, 5] => это вектор
- [[1], [2], [3], [4], [5]] => это вектор векторов, т. е. матрица/массив (в этом случае только с одним признаком для каждого объекта)
- [[1, 10], [2, 20], [3, 30], [4, 40], [5, 50]] => это вектор векторов, то есть матрица (в данном случае два признака для каждого объекта)
Код
X = df[ ['len_name'] ].values
y = df['target'].values
model = DummyClassifier()
model.fit(X, y)
y_pred = model.predict(X)
Так как у нас уже есть массив X (признаки для наших объектов) и вектор y (ответы для объектов или целевая переменная [англ. target variable]), то мы уже можем начать строить модель.
Этот процесс состоит из простых трех шагов:
Кстати, обычно ответ из модели присваивается переменной y_pred (конечно, Ты можешь назвать эту переменную, как хочешь), но я рекомендую придерживаться этого соглашения.
Теперь мы можем назначить y_pred в новый столбец и посмотреть, сколько он отобрал мужских имен и сколько женских.
Этот процесс состоит из простых трех шагов:
- Выбор модели (алгоритма) и создание экземпляра
- Обучение модели (с указанием X и y) => fit(X_train, y_train)
- Предсказание модели (в этом случае мы даем только признаки, потому что ответ возвращает модель) => predict(X_test)
Кстати, обычно ответ из модели присваивается переменной y_pred (конечно, Ты можешь назвать эту переменную, как хочешь), но я рекомендую придерживаться этого соглашения.
Теперь мы можем назначить y_pred в новый столбец и посмотреть, сколько он отобрал мужских имен и сколько женских.
Код
df['gender_pred'] = y_pred
df['gender_pred'].value_counts()
Результат:

Теперь давай посмотрим, во скольких случаях модель дала другой ответ, а не тот, который был на самом деле.
Код
df[ df.target != y_pred ].shape # неправильный ответ
Результат:
(810, 5)
(810, 5)
Помни, что 1 означает мужское имя, а 0 означает женское имя.
Обрати внимание, во скольких случаях (df[ df.target != y_pred ].shape) из 1705 наша модель ошиблась. Модель была настолько "умна", что только учитывала прошлое распределение (напомню, что было 1033 против 672), и именно поэтому модель решила, что мужское имя должно быть чаще. Конечно, такой подход ошибочен... но уже можно сделать интересные выводы о том, как легко искажать реальность модели, давая определенные данные чаще или реже.
Кстати, интересная статья о том, что данные не являются абсолютной истиной.
Следующим шагом является измерение качества. Для простоты мы рассмотрим accuracy, то есть точность нашей модели (на данный момент мы оставим другие возможные метрики, чтобы упростить начало).
Обрати внимание, во скольких случаях (df[ df.target != y_pred ].shape) из 1705 наша модель ошиблась. Модель была настолько "умна", что только учитывала прошлое распределение (напомню, что было 1033 против 672), и именно поэтому модель решила, что мужское имя должно быть чаще. Конечно, такой подход ошибочен... но уже можно сделать интересные выводы о том, как легко искажать реальность модели, давая определенные данные чаще или реже.
Кстати, интересная статья о том, что данные не являются абсолютной истиной.
Следующим шагом является измерение качества. Для простоты мы рассмотрим accuracy, то есть точность нашей модели (на данный момент мы оставим другие возможные метрики, чтобы упростить начало).
Код
accuracy_score(y, y_pred)
Результат:
0.5249266862170088
0.5249266862170088
Мы имеем около 50% - результат очень близкий к случайному (50% мы всегда можем получить, просто бросив монету).
Внимание! accuracy_score проверяет, сколько значений для вектора y_pred совпадает с вектором y и показывает результат в процентах. Подробнее о метриках будет в следующем модуле.
Случайность
DummyClassifier игнорирует функции и возвращает всегда тот же результат, если установить random_state. Если же его не установить random_state, то результат будет немного отличаться каждый раз (можешь проверить :)).
Внимание! accuracy_score проверяет, сколько значений для вектора y_pred совпадает с вектором y и показывает результат в процентах. Подробнее о метриках будет в следующем модуле.
Случайность
DummyClassifier игнорирует функции и возвращает всегда тот же результат, если установить random_state. Если же его не установить random_state, то результат будет немного отличаться каждый раз (можешь проверить :)).
Код
model = DummyClassifier(random_state=0)
model.fit(X, y)
y_pred = model.predict(X)
accuracy_score(y, y_pred)
Результат:
0.5237536656891496
0.5237536656891496
Линейная модель
Теперь давай использовать линейную модель LogisticRegression (помни, что логистическая регрессия - это линейная регрессия + в конце двоичная функция, которая возвращает 0 или 1).
Есть много параметров, которые можно уточнить для модели. В этом случае мы определим только solver, то есть алгоритм, который используется для вычисления модели. На этом этапе не имеет большого значения, какой мы выберем, поэтому мы будем использовать значение по умолчанию для LogisticRegression.
Кстати, название LogisticRegression довольно запутанное, потому что само название указывает на выполнение регрессии, однако на самом деле происходит классификация. Откуда такое название? Как это часто бывает в жизни - так исторически сложилось.
Может быть, я еще раз повторю, на всякий случай LogisticRegression - это линейная модель для классификации (не регрессии). Имя модели, такое как есть, стоит запомнить:).
Теперь давай использовать линейную модель LogisticRegression (помни, что логистическая регрессия - это линейная регрессия + в конце двоичная функция, которая возвращает 0 или 1).
Есть много параметров, которые можно уточнить для модели. В этом случае мы определим только solver, то есть алгоритм, который используется для вычисления модели. На этом этапе не имеет большого значения, какой мы выберем, поэтому мы будем использовать значение по умолчанию для LogisticRegression.
Кстати, название LogisticRegression довольно запутанное, потому что само название указывает на выполнение регрессии, однако на самом деле происходит классификация. Откуда такое название? Как это часто бывает в жизни - так исторически сложилось.
Может быть, я еще раз повторю, на всякий случай LogisticRegression - это линейная модель для классификации (не регрессии). Имя модели, такое как есть, стоит запомнить:).
Код
model = LogisticRegression(solver='lbfgs')
model.fit(X, y)
y_pred = model.predict(X)
accuracy_score(y, y_pred)
Результат:
0.6058651026392962
0.6058651026392962
Как видишь, качество модели уже лучше. Нам удалось достичь ~61% точности. Давай посмотрим, как выглядят варианты ответов.
Код
df['gender_pred'] = y_pred
df['gender_pred'].value_counts()
Результат:
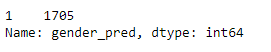
Это означает, что модель всегда возвращала 1 (Каждое имя - мужское имя), потому что именно этот класс был более популярным. Давай проведем эксперимент, если прописать вручную значение 1, тогда получится тот же результат.
Код
y_pred = [1]*X.shape[0] #количество единиц должно совпадать с количеством строк в матрице X
accuracy_score(y, y_pred)
Результат:
0.6058651026392962
0.6058651026392962
Почему так происходит?
По текущим признакам линейная модель не смогла обучиться лучше и посчитала такой подход наиболее разумным.
Почему accuracy в порядке. 61% при таком неразумном подходе? Это связано со слабостью этой метрики, которая сильно зависит от распределения (подробнее об этом во втором модуле).
Сейчас добавим еще один признак, но уже можно заметить, что предыдущая ячейка, состоящая из 4 строк кода, будет повторяться. Это означает, что стоит сделать отдельную функцию, чтобы облегчить жизнь в будущем. Пусть это будет функция с именем: train_and_predict_model.
По текущим признакам линейная модель не смогла обучиться лучше и посчитала такой подход наиболее разумным.
Почему accuracy в порядке. 61% при таком неразумном подходе? Это связано со слабостью этой метрики, которая сильно зависит от распределения (подробнее об этом во втором модуле).
Сейчас добавим еще один признак, но уже можно заметить, что предыдущая ячейка, состоящая из 4 строк кода, будет повторяться. Это означает, что стоит сделать отдельную функцию, чтобы облегчить жизнь в будущем. Пусть это будет функция с именем: train_and_predict_model.
Код
def train_and_predict_model(X, y, model, success_metric=accuracy_score):
model.fit(X, y)
y_pred = model.predict(X)
print("Distribution:")
print( pd.Series(y_pred).value_counts() )
return success_metric(y, y_pred)
Внимание!
Мы можем вызвать success_metric(y, y_pred), что и в предыдущей версии, success_metric=accuracy_score означает, что accuracy_score получит те же параметры, которые мы передали в success_metric. Python позволяет передавать параметры по умолчанию для функции таким образом (что невозможно, например, на таких языках, как Java или PHP, но это нормально для всех функциональных языков).
Признаки
Поработаем над гласными. Возможно, их количество и порядок влияют на то, мужское это имя или женское.
Мы можем вызвать success_metric(y, y_pred), что и в предыдущей версии, success_metric=accuracy_score означает, что accuracy_score получит те же параметры, которые мы передали в success_metric. Python позволяет передавать параметры по умолчанию для функции таким образом (что невозможно, например, на таких языках, как Java или PHP, но это нормально для всех функциональных языков).
Признаки
Поработаем над гласными. Возможно, их количество и порядок влияют на то, мужское это имя или женское.
Код
vowels = ['a', 'ą', 'e', 'ę', 'i', 'o', 'u', 'y']
def how_many_vowels(name):
count = sum( map(lambda x: int(x in vowels), name.lower()) )
return count
#how_many_vowels('Jana')
df['count_vowels'] = df['name'].map(how_many_vowels)
train_and_predict_model(df[['len_name', 'count_vowels'] ], y, LogisticRegression(solver='lbfgs'))
Результат:
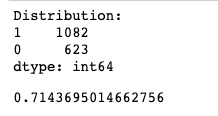
Удалось улучшить результат на 10 процентных пунктов! Очень хорошо, давай продолжим. Новая функция будет проверять, является ли первая буква гласной или нет.
Обрати внимание, что распределение ответов уже достаточно разумно 1082 vs 623 (не только "1" (мужские имена), но и женские).
Обрати внимание, что распределение ответов уже достаточно разумно 1082 vs 623 (не только "1" (мужские имена), но и женские).
Код
def first_is_vowel(name):
return name.lower()[0] in vowels
#first_is_vowel('Ada')
df['first_is_vowel'] = df['name'].map(first_is_vowel)
train_and_predict_model(df[['len_name', 'first_is_vowel'] ], y, LogisticRegression(solver='lbfgs'))
Результат:
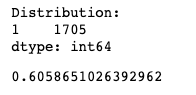
Как можно увидеть, эта особенность не повлияла на качество модели вообще... Это нормально. На самом деле довольно часто мы будем пробовать разные идеи, и большинство из них могут не сработать. Нужно быть готовым к этому и жить по принципу: Fail fast, learn faster . . .
Обрати внимание, что на этот раз модель вернула только "1" (мужское имя), то есть она не могла "придумать" ничего лучше. Это означает, что признак "является ли первая буква гласной?" - это бесполезный вариант (для линейной модели).
Идем дальше. Теперь давай проверим вместе три признака: длина имени, количество гласных и является ли первая буква гласной.
Обрати внимание, что на этот раз модель вернула только "1" (мужское имя), то есть она не могла "придумать" ничего лучше. Это означает, что признак "является ли первая буква гласной?" - это бесполезный вариант (для линейной модели).
Идем дальше. Теперь давай проверим вместе три признака: длина имени, количество гласных и является ли первая буква гласной.
Код
X = df[['len_name', 'count_vowels', 'first_is_vowel'] ]
train_and_predict_model(X, y, LogisticRegression(solver='lbfgs'))
Результат:
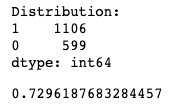
Удалось улучшить модель еще на один 1.5% (0.714 vs 0.729). Очень хорошо, мы идем дальше.
Только сначала давай лучше узнаем функцию .factorize ()
Только сначала давай лучше узнаем функцию .factorize ()
Код
pd.factorize(['blue', 'green', 'yellow', 'blue'])
Результат:
(array([0, 1, 2, 0]), array(['blue', 'green', 'yellow'], dtype=object))
(array([0, 1, 2, 0]), array(['blue', 'green', 'yellow'], dtype=object))
Как видишь, pd.factorize() вернул tuple с двумя результатами.
- во-первых, - это уникальный ID array([0, 1, 2, 0])
- во-вторых, - это метки для идентификаторов, см. blue=0 или yellow=2 (т. е. yellow имеет индекс два в массивах ['blue', 'green', 'yellow'])
Код
pd.factorize(['blue', 'green', 'yellow', 'blue'])[0]
Результат:
array([0, 1, 2, 0])
array([0, 1, 2, 0])
Функцию .factorize() мы можем записать так: pd.factorize() или так: df ['new_column'].factorize (). Результат выполнения будет идентичным, но второй вариант иногда удобнее писать.
Давай вернемся к нашим признакам и присвоим каждой букве уникальный идентификатор.
Давай вернемся к нашим признакам и присвоим каждой букве уникальный идентификатор.
Код
df['first_letter'] = df['name'].map(lambda x: x.lower()[0])
df['first_letter_cnt'] = df['first_letter'].factorize()[0]
X = df[['len_name', 'count_vowels', 'first_is_vowel', 'first_letter_cnt'] ]
train_and_predict_model(X, y, LogisticRegression(solver='lbfgs'))
Результат:
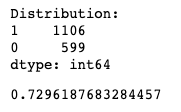
Задача 1.3.2
Напиши аналогичный код, как указано выше, только извлеки последнюю букву в качестве признака (вместо первой).
В уроке курса (на сервере Jupyter) для задания предусмотрена подсказка и ответ - по умолчанию скрыты :))
Напиши аналогичный код, как указано выше, только извлеки последнюю букву в качестве признака (вместо первой).
В уроке курса (на сервере Jupyter) для задания предусмотрена подсказка и ответ - по умолчанию скрыты :))
Новые идеи для новых признаков
- Давай возьмем все гласные (англ. vowels), предполагая, что это может повлиять на результат. Например, Sławomir имеет три гласных в этом порядке: аоi, в то время как Патриция также имеет три гласных, но другое сочетание: аия (только дальше будет на польском). Для каждой комбинации появится уникальный идентификатор.
- Давай сделаем то же самое и для согласных букв (англ. consonants).
Код
def get_all_vowels(name):
all_vowels = [letter for letter in name.lower() if letter in vowels]
return ''.join(all_vowels)
#get_all_vowels('Sławomir')
df['all_vowels'] = df['name'].map(get_all_vowels)
df['all_vowels_cnt'] = pd.factorize(df['all_vowels'])[0]
X = df[['len_name', 'count_vowels', 'first_is_vowel', 'first_letter_cnt', 'all_vowels_cnt'] ]
train_and_predict_model(X, y, LogisticRegression(solver='lbfgs'))
Результат:

Код
def get_all_consonants(name):
all_consonants = [letter for letter in name.lower() if letter not in vowels]
return ''.join(all_consonants)
#get_all_consonants('Sławomir')
df['all_consonants'] = df['name'].map(get_all_consonants)
df['all_consonants_cnt'] = pd.factorize(df['all_consonants'])[0]
X = df[['len_name', 'count_vowels', 'first_is_vowel', 'first_letter_cnt', 'all_consonants_cnt'] ]
train_and_predict_model(X, y, LogisticRegression(solver='lbfgs', max_iter=200))
Результат:

Немного лучше (особенно первая идея с гласными буквами): 0.729 vs 0.738. Согласные буквы немного улучшили модель, но не так сильно: 0.729 vs 0.731. В этом есть смысл, не так ли? Гласные оказывают большее влияние на то, является ли имя мужским или женским.
Продолжим думать. Еще одна особенность, которая может повлиять, - это то, какой тип у последней буквы (согласная или гласная). Если это гласная, то скорее всего - это женское имя, например: Kamila и Kamil, Adriana и Adrian или Jana и Jan. Давай проверим.
Продолжим думать. Еще одна особенность, которая может повлиять, - это то, какой тип у последней буквы (согласная или гласная). Если это гласная, то скорее всего - это женское имя, например: Kamila и Kamil, Adriana и Adrian или Jana и Jan. Давай проверим.
Код
def last_is_vowel(name):
return name.lower()[-1] in vowels
#last_is_vowel('Ada')
df['last_is_vowel'] = df['name'].map(last_is_vowel)
X = df[['last_is_vowel'] ]
train_and_predict_model(X, y, LogisticRegression(solver='lbfgs', max_iter=200))
Результат:
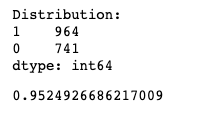
Вау! Ты это видишь? Только одна особенность может сразу дать такой хороший результат- 95%. Вот почему процесс feature engineering является таким важным процессом.
Нужно привыкнуть к тому, что сначала нужно напрягаться, но есть шанс, что именно с помощью метода проб и ошибок сможешь придумать очень разумный признак.
Кстати, можешь ли вспомнить мужское имя, которое заканчивается на "а"?
Нужно привыкнуть к тому, что сначала нужно напрягаться, но есть шанс, что именно с помощью метода проб и ошибок сможешь придумать очень разумный признак.
Кстати, можешь ли вспомнить мужское имя, которое заканчивается на "а"?
Код
feats = ['last_is_vowel', 'len_name', 'count_vowels', 'first_is_vowel', 'all_vowels_cnt', 'all_consonants_cnt']
X = df[ feats ]
train_and_predict_model(X, y, LogisticRegression(solver='lbfgs', max_iter=200))
Результат:
Интересный факт
Давай посмотрим, как часто мужское имя заканчивается на букву "А", а женское имя не заканчивается на букву"А".
Давай посмотрим, как часто мужское имя заканчивается на букву "А", а женское имя не заканчивается на букву"А".
Код
df.columns
Результат:

Код
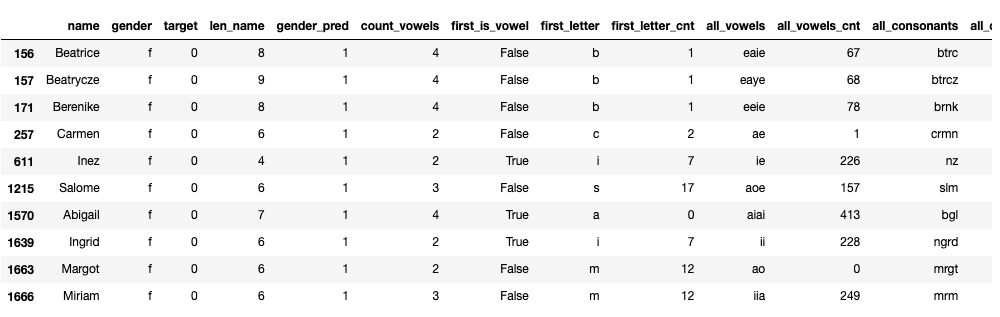
df['lst_letter_a'] = df.name.map(lambda x: x[-1] == 'a')
df[ (df.gender == 'm') & df.lst_letter_a ]
Результат:

У нас есть 4 мужских имени, которые заканчиваются на букву "А".
Посмотрим, сколько женских имен не заканчивается буквой "А".
Обрати внимание, что символ тильды ~ отрицает символ, то есть (~df.lst_letter_a) является тем же, что и (False == df.lst_letter_a)
Посмотрим, сколько женских имен не заканчивается буквой "А".
Обрати внимание, что символ тильды ~ отрицает символ, то есть (~df.lst_letter_a) является тем же, что и (False == df.lst_letter_a)
Код
df[ (df.gender == 'f') & (~df.lst_letter_a) ]
Результат:
Среди этих 10 имен, которые не заканчиваются на "А", сколько польских? :)
Должен признаться, этот результат немного оптимистичен. Почему? Это хороший вопрос. Подумай над этим.
Помни, что тренировать модель и проверять ее на тех же данных - это плохая идея. Это так же, как приходить на экзамен и вместе с вопросами получить ответы.
Этот эффект называется переобучением (англ. overfitting) и создает довольно большие проблемы в машинном обучении. Чтобы справиться с этим, нужно учиться!
Мы справимся спокойно. Уже в следующем уроке я покажу Тебе первый способ справиться с этим, а в следующем модуле мы потратим еще больше времени, чтобы понять это.
Как я уже сказал, - это одна из самых больших "проблем" в машинном обучении, которая сводится к вопросам: "могу ли я доверять модели? Эта модель действительно работает (достаточно) хорошо?".
Должен признаться, этот результат немного оптимистичен. Почему? Это хороший вопрос. Подумай над этим.
Помни, что тренировать модель и проверять ее на тех же данных - это плохая идея. Это так же, как приходить на экзамен и вместе с вопросами получить ответы.
Этот эффект называется переобучением (англ. overfitting) и создает довольно большие проблемы в машинном обучении. Чтобы справиться с этим, нужно учиться!
Мы справимся спокойно. Уже в следующем уроке я покажу Тебе первый способ справиться с этим, а в следующем модуле мы потратим еще больше времени, чтобы понять это.
Как я уже сказал, - это одна из самых больших "проблем" в машинном обучении, которая сводится к вопросам: "могу ли я доверять модели? Эта модель действительно работает (достаточно) хорошо?".
Это пример теории одного из уроков первого модуля нашего курса по Data Science.
К каждому уроку еще полагается:
Приглашаем принять участие в авторском 4-х недельном курсе по Data Science.
К каждому уроку еще полагается:
- написание кода (c пояснением),
- домашние задания (со скрытыми подсказками и ответами),
- полезные ссылки,
- ответы на любые вопросы.
Приглашаем принять участие в авторском 4-х недельном курсе по Data Science.
